In this post I detail a structural change in a web application which involves delayed scheduling of job execution. In the legacy design, each application node maintained its own job queue using standard Java high-level concurrency features. We migrated the application to use Quartz Job Scheduler, which enabled us eventually to offload the persistence of job scheduling details and other metadata to Redis running on Amazon Elasticache. De-coupling job creation, scheduling and execution allowed for more flexibility in taking application nodes out of service, and provides improved resilience for scheduled job metadata in the event of application node failure.
Logic Squad has a web application with a feature that allows a user to create a set of notifications that are sent after a delay. Our initial implementation involved each application node handling its own scheduling using a ScheduledExecutorService, meaning that a delayed task was held in-memory by the node that created it, and later executed by that same node. This worked well for some time, but always imposed an obvious impediment: a node couldn’t be shut down (for example, to upgrade the application) until its queue had drained, and with tasks that could be delayed up to 36 hours, this was a significant downside to that approach.
We wanted to de-couple notification queuing and sending from the main application. Our initial thoughts centred on a stand-alone web service that would handle this—a reasonable idea, but one which would involve a non-trivial amount of work to build from scratch. Meanwhile, in some other contexts, we had started using Quartz Job Scheduler to provide cron-like scheduling of jobs. Of course, Quartz can also provide simpler, one-off delayed scheduling—this was interesting, but didn’t seem to buy us much more than ScheduledExecutorService. It was only when I ran into Quartz’s JDBCJobStore, and the idea of using the database for delayed job persistence that I realised we didn’t need to build a completely stand-alone solution, we just needed to be able to persist the schedule and some metadata about the delayed job.
The original application structure looked like this, with individual application nodes responsible for not only creating, but storing and later executing their own jobs.
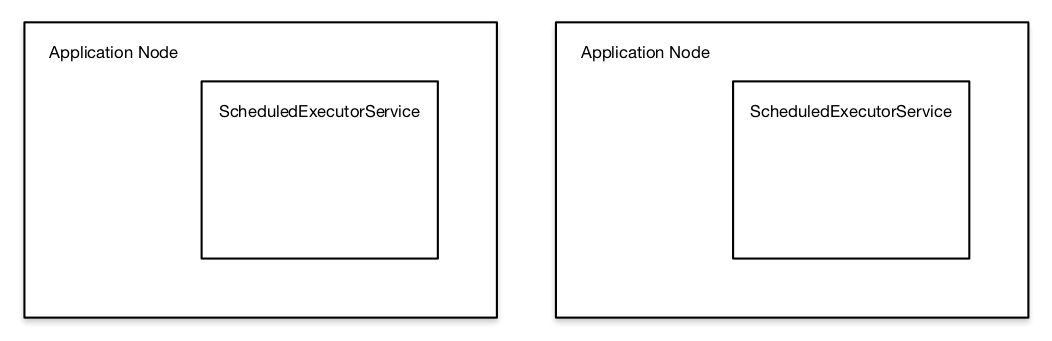
Not only did this make it difficult to intentionally bring down a node, but an application crash would mean the loss of every delayed job in that node’s queue.
The first step in the transition process was migrating to Quartz and using the RAMJobStore. This bought us nothing compared to our existing system, beyond requiring the migration from Runnables to Quartz Jobs. Instead of submitting a Runnable to the ScheduledExecutorService, we re-wrote some modules to submit a Quartz Job to the Scheduler. At the end of this stage, we had a very similar structure (with essentially the same weaknesses), but dependent on Quartz instead of java.util.concurrent.
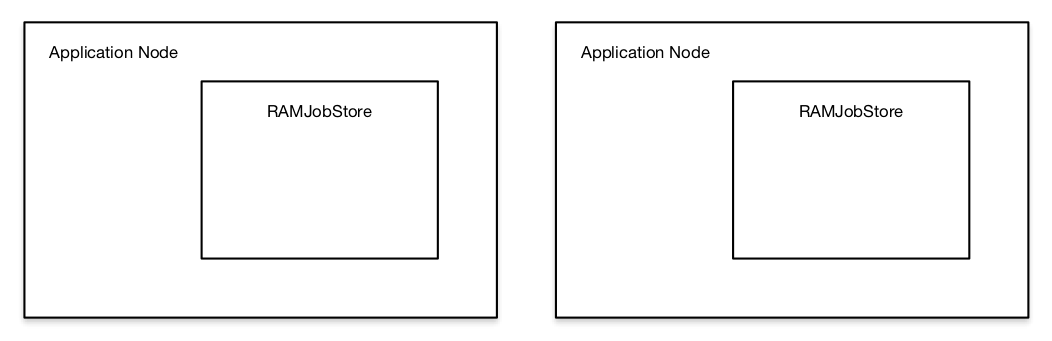
The initial idea was that the next step would be to migrate to JDBCJobStore, backed by the PostgreSQL. database we were already using (by way of Amazon RDS). Testing in development was very successful. There were a couple of sticking points, though.
- Adding additional tables to an otherwise application-focused database.
- Setting up those tables automatically on next application launch—we are heavily committed to code-based database migrations, and didn’t want manually-applied SQL scripts lying around.
I started to investigate some Java options for database migration, and just as I was going to begin some proof-of-concept testing, I ran into the idea of using non-database persistence. Options appeared to include:
- Amazon SimpleDB
- A RedisJobStore from Redis Labs
- A fork of RedisJobStore
- Amazon DynamoDB
We went with the forked RedisJobStore, as, frankly, it looked the least like abandonware of all of those projects.
An impressive feature of Quartz at this point was that flipping over from RAMJobStore to RedisJobStore involved only changing a handful of properties—no code changes were required. We were testing on Redis (hosted in a FreeBSD VM on VMWare Fusion) in the morning, and Elasticache in the afternoon.

We had already migrated a couple of application nodes in production to use Quartz backed by the RAMJobStore. Operation was indistinguishable from the remaining nodes using ScheduledExecutorService—obviously, this was exactly the desired outcome. After a day or so, we migrated a single node to use RedisJobStore backed by Elasticache. Again, there were no issues, and several days later we migrated a second node.
In the first few days, there were two issues. In the QuartzSchedulerThread, we were seeing a few JedisConnectionExceptions arising from:
- Read timeouts.
- An apparent failure to get
Jedisobjects from theJedisPool.
RedisJobStore configuration seems a little undercooked. Some of the parameters are configurable via properties, but others, including socket read timeout and JedisPool size are hard-coded. We worked around this by subclassing RedisJobStore, overriding initialize(), calling super.initialize() and then replacing the JedisPool with a new one.
public void initialize(ClassLoadHelper loadHelper,
SchedulerSignaler signaler) throws SchedulerConfigException {
super.initialize(loadHelper, signaler);
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
// maxTotal defined elsewhere
jedisPoolConfig.setMaxTotal(maxTotal);
// timeout defined elsewhere
JedisPool newPool = new JedisPool(jedisPoolConfig, host, port,
timeout, password, database, ssl);
setJedisPool(newPool);
return;
}The hard-coded values are 2,000ms for timeout and 8 for maxTotal, so we started by bumping these to 5,000ms and 16. We’re still measuring the effect of these changes.
The new Quartz-Elasticache solution is running on about a third of the total nodes for this application, and has been performing with only the early timeout/resource issues described above for a total of about 20 node-days. We plan to monitor for those and any other issues for at least a few more days, and then migrate the remaining nodes to the new system.
